R 講題分享 – SpideR -- 用R自製網路爬蟲收集資料 (作者:Taiwan R User Group)
大家好,這篇文章是取材自EC於10月份在Taiwan R User Group的分享內容。他從社群過去分享的內容中學習,撰寫了一個網路爬蟲來收集中國的新聞。以下是他的心得分享。
工具
EC主要是利用以下的R套件來達成任務:
Rcurl
Rcurl是提供R使用網際網路上各種通訊協定的工具。EC主要是透過Rcurl來製作Query的格式來自動化下載網站內容的動作。
XML
下載後的內容是HTML格式,無法直接分析。所以EC再利用XML套件的readHTMLTable和XPath的功能來將需要的資訊從文件中萃取出來。
RMessenger(監控用, powered by Wush)
由於要爬的資料很大,EC需要使用很多機器跑數天的程式。又因為網路環境很容易出錯,EC需要有工具在出錯的時候通知他。RMessenger是提供R傳送即時訊息的功能,讓EC能在第一時間得知出錯的狀況。
結果
最後EC總共發出了1,538,992 個Queries和抓取了25,828,673 篇文章。
注意事項
以下的兩大原則可以讓大家避免潛在的麻煩。
版權所有原則
抓取資料前,應先檢視網站對於抓取與運用資料的宣告。即便網站中沒有明確的版權聲明、資料可公開為所有人自由擷取且現行法規對於電子著作權的保護仍模糊的情境下,但我方在應用抓下的資料時,仍應假定該網站擁有所有的版權(All Rights Reserved)。
盡量匿蹤原則
爬蟲程式可以說是駭客行為(Hacking)的一種,我們可以將它定義為「採取跳脫常規的作法,以有創意的方式抓取網頁資料的程序」。由定義可知,爬蟲程式是一種正面的作為,但由於它通常會耗用掉網站的大量資源(網路法律界引入了「侵入動產(trespass to chattels)」的概念,其意指他人阻止或損害擁有者使用其財產的權益。),因此爬蟲程式並不為網站擁有者所樂見。對此,我方應儘量善待對方的網路資源,且盡可能偽裝成一般使用者,以免帶來不必要的法律困擾且讓爬蟲程式可以長久運作。以下是一些相關的心得:
- 儘量第一次發Query就做對,不要有太多異常的Query。
- 尊重和珍惜網路流量資源。不要吃光對方的流量,也不要干擾到對方的正常服務。
- 可以用Proxy服務作跳板,如TOR,但是請小心謹慎的使用,珍惜公共資源。
- 儘量在使用者多得時候混在使用者中,避免在離峰時間出沒以免被注意。
- 發Query的行為儘量偽裝成正常使用者,如:
- 每抓取一筆資料後,隨機等待一段時間後再行動(使用 sleep + rand 函數)。
- 每天自不同的時間開始行動,亦即系統排程不要太有規律。
- 限制每天抓取的總流量,這樣才能細水長流。
抓取網頁資料的標準作業程序
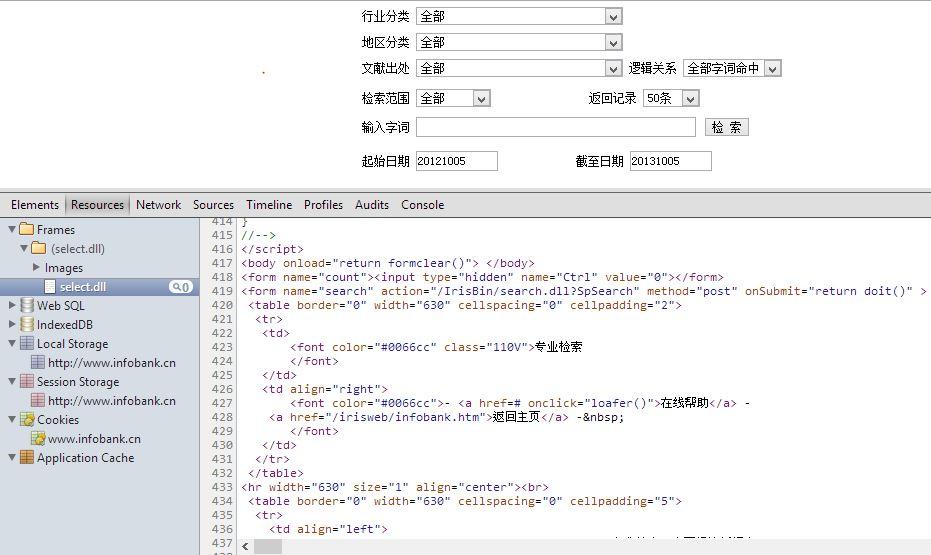
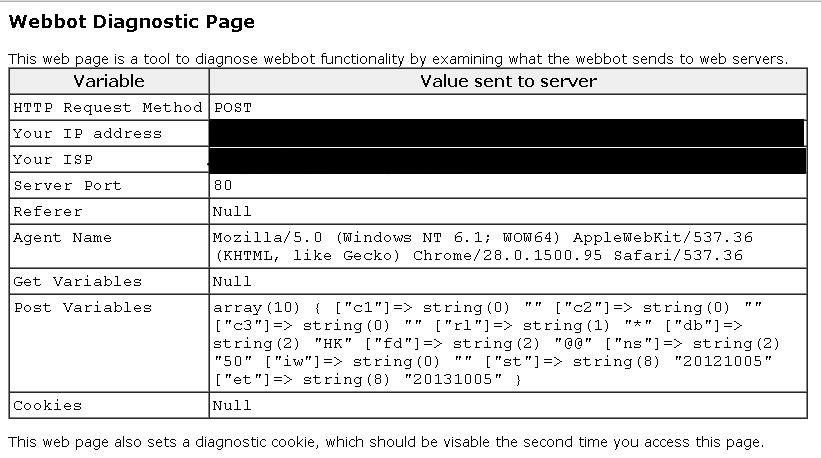
分析網頁的表單(Form)格式(逆向工程),以製定Query格式
分析表單的細節解說請參考c3h3於TW use-R在20130818 MLDM spideR的演講。在此演講中,EC分享了兩個工具來分析網頁:
處理抓下來的資料
由於不熟悉Encoding的知識,開發者常常需要花費大量的時間在處理Encoding的問題。尤其處理到中文資料時,不同作業系統預設的Encoding也不相同,往往讓開發者看到亂碼而八丈摸不著頭緒,以為是資料抓錯了。EC介紹了一些關於Encoding的知識:
什麼是Charcter Encoding/字元編碼/字符編碼
文字資料儲存到電腦後,最終都是0和1的位元序列。Encoding則是電腦用來把位元序列轉譯成人類看得懂的文字的格式。例如下圖就表示數種不同Encoding表示「我愛你」的位元序列格式:
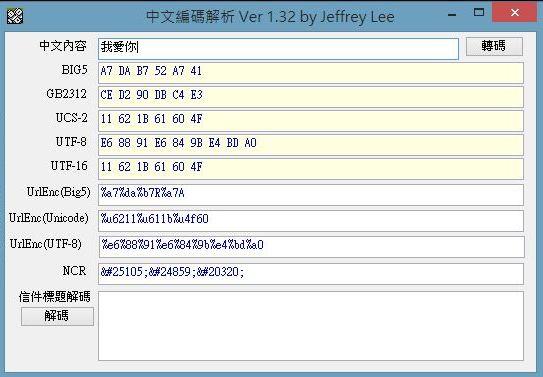
ps. 一般表示序列的時候,會使用16進位的符號來簡化表示位元序列。如: - 1 代表 0001 - 8 代表 1000 - F 代表 1111
所以如果Encoding的設定不正確,電腦就沒辦法把資料正確的轉換成文字供人類閱讀。
作業系統使用的繁體中文Encoding
當我們在處理中文資料時,很不幸的,不同作業系統預設的中文編碼是不同的。
Windows系統預設是Big5,Linux系統預設則是UTF-8,所以如果在Linux上處理Windows中撰寫的中文檔案,很大的機會會看到亂碼。
R IDE的Encoding
除了作業系統預設的編碼不同外,R IDE的預設編碼在不同的作業系統下亦有不同的編碼方式,這可能是源自於預設安裝的設定不同,也可能因為使用者安裝後自行做了修改。以RStudio為例,其在Windows/Mac/Linux等作業系統下的編碼方式可能不同的設定(使用者可以透過Menu->Tools->Global Options->General->Default text encoding查看),稍後會介紹Sys.getlocale()或sessionInfo()函數查詢Ecoding的設定。
讀取檔案或網頁的Encoding
若開啟的檔案或下載的網頁有亂碼的問題,通常係發送端與接收端的Encoding設定不同所致。亂碼除了極難閱讀外,更甚者,會使程式因為讀到特殊字元而致使載入資料不完全或異常中斷,這些錯誤都不易除錯。對此,有國外的技術論壇建議以「UTF-8(檔首無BOM)」進行編碼比較能避免錯誤發生。
R 如何處理Encoding
以下精要彙整此次開發spideR中,使用到與Encoding有關的R 相關函數:
- 查詢現行環境下的Encoding設定
- Sys.getlocale()
- sessionInfo()
- 修改現行環境下的Encoding設定
Sys.setlocale() :例如:Sys.setlocale(category='LC_ALL', locale='C')
- 以特定Encoding載入文字檔
- read.table() :例如:myStrVec <- read.table(myFile, ... , encoding='UTF-8')
- 載入特定檔後轉換Encoding
- Encoding() :例如:Encoding(myStrVec) <- 'gb2312'
- iconv() :例如:myURL <- iconv(myStrVec[i], from='UTF-8', to='gb2312')
- 送出Query URL的Encoding
- URLencode() :例如:myURL <- URLencode(myURL)
- 接收Query結果的Encoding
- getURL() :例如:myRes <- getURL(myURL, ... , .encoding='gb2312')
- readLines() :例如:myRes <- readLines(myURL, encoding='gb2312')
readHTMLTable() :例如:myRes <- readHTMLTable(myRes, encoding='gb2312', which= ...)
當R IDE 開發spideR 面對Encoding 的解決方案
EC寫這支spideR程式共花了七天,但卻有五天是在嘗試解決上述Encoding所導致的問題。經過了幾經的嘗試與搜尋國外的技術論壇(特別推薦Stack Overflow )後,建議一個可以避免Encoding的解決方案供大家參考。
- 程式開始處,先將Encoding 轉成選項'C'
- Sys.setlocale(category='LC_ALL', locale='C')
- 中間依據需求統一轉成特定編碼
- myStrVec = read.table('myFile.csv', sep=',', ... , encoding='UTF-8')
- myStr <- iconv(myStrVec[i], from='UTF-8', to='gb2312')
- myURL <- URLencode(myStr)
- myRes <- getURL(myURL, ... , .encoding='gb2312')
- myRes <- readHTMLTable(myRes, encoding='gb2312', which= ...)
- 程式結尾處再轉回原Encoding 設定,選項為''(此步驟可略)
- Sys.setlocale(category='LC_ALL', locale='')
參考資料
- Taiwan R User Group
- 20130818 MLDM spideR (Ronny Wang)
- 20130325 MLDM spideR -1 (c3h3)
- 20130325 MLDM spideR -2 (c3h3)
- Schrenk, M. (2012), Webbots, Spiders, and Screen Scrapers: A Guide to Developing Internet Agents with PHP/CURL, 2nd Edition, No Starch Press.
- COS 統計之都的RCurl引介
- Stack Overflow (很好的技術論壇)
- inside-R (比較美觀的 R 文件)
- 維基百科
- 网页爬虫-R语言实现,函数库文件 (DataGuru 煉數成金 )
- 矛與盾大對決 (PHP Conf. Taiwan 2013)
- 金融業菜鳥實習生的 Python Project 初體驗
作者
Wush Wu ()
- Taiwan R User Group Organizer
- R 相關著作:
- 研究領域:Large Scale Learning,Text Mining和Uncertain Time Series
Yi-Hsi (EC) Lee ()
- 中山大學財務管理博士(2003-2010)
- 中南大學管理與科學博士候選人(2009-迄今)
- 志方財務顧問有限公司總經理
- R 相關著作:
- spideR-中國新聞網
- spideR-eBay
- 研究領域:金融風險管理模型與系統開發、投資決策支援系統開發